

Prophet Inequalities
Posted: 2018-08-24.
So-called "Prophet Inequalities" are cute mathematical stopping-time theorems with interesting applications in mechanism design. The problem is to choose when to stop and claim an arriving random variable, performing almost as well as if you had prophetic foresight.
Setup
Practical Polly will observe a sequence of nonnegative random variables $X_1,\dots,X_n$. She knows the distribution of each of these random variables, and they are drawn independently. As each one arrives, she observes its actual value and gets to decide whether to stop and keep it, or let it go and continue. For example, maybe she sees $X_1 = 7$ and says continue. She sees $X_2 = 4$ and says continue. She sees $X_3 = 51$ and says stop. She gets a value of $51$. She wants to come up with a strategy having high expected performance.
Now meet Prophetic Pam. Pam sees in advance the realizations of all the variables. So Pam can foretell exactly the right time to stop. She always gets \[ \max_i X_i \] How much better does the prophet Pam do than Polly?
The Optimal Dynamic Policy
Let's start by describing Polly's optimal algorithm and what approximation ratio it can guarantee. Later we'll discuss simpler policies.
If Polly gets to the last variable, $X_n$, she should always take it. So the expected value of the optimal policy conditioned on reaching time $n$ is $V_n := \mathbb{E} X_n$.
If Polly reaches time $n-1$, she has to decide whether to take $X_{n-1}$ or reject it and continue. We have already seen that she gets $V_n$ for continuing, so she should use a threshold policy: If $X_{n-1} \geq V_n$, take it, otherwise, continue. This gives her expected value $V_{n-1} := \mathbb{E} \max\{X_{n-1},V_n\}$ for reaching step $n-1$. Similarly $V_{n-2} = \mathbb{E} max\{X_{n-2}, V_{n-1}\}$ and so on.
We can picture this with a trick we've seen before, thresholds and bonuses. Let $b_i = (X_i - V_{i+1})^+$, where this notation means zero or $X_i - V_{i+1}$, whichever is larger. (For the last time step $n$, we can set $V_{n+1} = 0$ and so $b_n = X_n$.) So at time step $i$, Polly expects to get $V_i = \mathbb{E} \max\{X_i, V_{i+1}\} = V_{i+1} + \mathbb{E} b_i$. Recursively, we get that $V_i = \mathbb{E}\sum_{j\gt i} b_j$, and the value of the optimal policy is \[ DynAlg = V_1 = \mathbb{E} \left[ b_1 + b_2 + \cdots + b_n \right] \]
Theorem. Polly's algorithm is a $0.5$-approximation to the prophet's, i.e. the optimal dynamic policy expects to achieve at least half of the largest $X_i$.
Proof. First, we notice that each $X_i$ is at most $b_i + V_{i+1}$. (With equality if $X_i$ exceeds $V_{i+1}$.) Next, we have $V_{i+1} = \mathbb{E} \sum_{j \gt i} b_j \leq DynAlg$. Putting these together: \begin{align} \mathbb{E} \max_i X_i &\leq \mathbb{E} \max_i \left(b_i + V_{i+1}\right) \\ &= \mathbb{E} \max_i \left(b_i + \mathbb{E}\sum_{j \gt i} b_j\right) \\ &\leq \mathbb{E} \max_i \left(b_i + DynAlg\right) \\ &= \mathbb{E} \left(\max_i b_i\right) + DynAlg \\ &\leq \mathbb{E} \left(\sum_i b_i\right) + DynAlg \\ &= 2\mathbb{E} DynAlg . \end{align}
Theorem. No algorithm can guarantee an approximation ratio strictly greater than $0.5$.
Proof. We give a family of instances, each getting larger and larger, where the approximation factor of any algorithm shrinks to $0.5$.
There are just two variables. $X_1 = 1$ with probability $1$. Meanwhile, $X_2 = 0$ with probability $1-p$, $X_2 = 1/p$ with probability $p$. Polly gets expected value $1$ no matter what: if she accepts $X_1$ then she gets $X_1 = 1$, and if she rejects it, she will keep $X_2$ which has expected value $1$. But the prophet gets to pick the max, which is $1/p$ with probability $p$ and $1$ otherwise. So the prophet gets $\mathbb{E}\max\{1,X_2\} = p(1/p) + (1-p)(1) = 2-p$.
By taking $p$ arbitrarily small, we get that Polly cannot guarantee any factor better than $0.5$.
(If you are not familiar with approximation algorithms, let me point out a subtlety. On the above instances, an algorithm achieves $\frac{1}{2-p}$ which is always greater than $0.5$. So it's not formally correct to say we proved no algorithm can beat $0.5$-fraction of the max. What we proved is there is no constant $c \gt 0.5$ such that the algorithm guarantees a $c$-fraction of the max.)
Simple Solutions
Getting an optimal policy is all well and good, but Polly wants to do better than that. What she really wants is a simple policy. Remarkably, we will see that a simple "single-threshold" stopping rule also guarantees half of the max value.
Let us consider a fixed threshold $V$ and the simple rule:
For a fixed threshold $V$, let's redefine the bonuses $b_i$. Let $b_i = (X_i - V)^+$ for each $i$. This is the amount by which $X_i$ exceeds the threshold, or zero if it doesn't. Let us also define $P = \Pr[ \max_i X_i \geq V ]$.
Lemma 1. The expected value achieved by the threshold algorithm (for a fixed $V$) is
\[ Alg \geq P V + (1-P)\mathbb{E} \sum_i b_i .\]Proof. Notice that we get the bonus of every variable up until we stop. It is zero for all the variables but the last one, of course, because they didn't exceed the threshold. So the probability we get $b_i$ is exactly the probability we rejected $X_1,\dots,X_{i-1}$. Meanwhile, in addition to these bonuses, we get $V$ itself as long as we take some variable. This happens with probability $P$. So
\begin{align} Alg = P V + \mathbb{E} \sum_i \Pr[\text{rejected all $j \lt i$}] b_i \end{align}Now, we have $\Pr[\text{rejected all $j \lt i$}] \leq 1-P$, which is the probability we rejected all variables. So
\[ Alg \geq P V + (1-P)\mathbb{E} \sum_i b_i \] (We used independence of the variables by assuming that the distribution of $b_i$ doesn't change when conditioning on rejecting $X_1,\dots,X_{i-1}$.)Lemma 2. For any fixed threshold $V$, the prophet's performance satisfies
\begin{align} \mathbb{E} \max_i X_i &\leq V + \mathbb{E} \sum_i b_i . \end{align}Proof. Each $X_i \leq b_i + V$. (We have equality if $X_i$ exceeds the threshold.) So
\begin{align} \mathbb{E} \max_i X_i &\leq \mathbb{E} \max_i \left(b_i + V\right) \\ &= \mathbb{E} \left(\max_i b_i\right) + V \\ &\leq \mathbb{E} \sum_i b_i + V . \end{align}Now we can pick a threshold and derive a guarantee for the simple threshold policy.
Theorem (Samuel-Cahn 1984). By picking threshold $V = $ the median of the random variable $\max_i X_i$, the threshold policy guarantees at least half of the prophet's value.
We are setting $V$ such that the probability that the maximum is weakly above $V$ is $0.5$. So $P = 0.5$ by definition, and $1-P = 0.5$. So by Lemma 1, \begin{align} Alg &\geq 0.5\left(V + \mathbb{E} \sum_i b_i\right) \\ &\geq 0.5 \mathbb{E} \max_i X_i \end{align} by Lemma 2.
Now, this proof is wrong if distributions have point masses. In that case, a median might cause $P \gt 0.5$. Exercise: Fix the algorithm and proof to deal with this case!
So a single threshold gives the same worst-case guarantee as the dynamic optimal policy! (That isn't to say it is always as good, of course.) But perhaps even more amazingly, there are other thresholds that also achieve the same guarantee.
Theorem (Kleinberg, Weinberg 2012). By picking threshold $V = 0.5 \mathbb{E} \max_i X_i$, the threshold policy guarantees at least half of the prophet's value.
By Lemma 2,
\begin{align} \mathbb{E} \sum_i b_i &\geq \mathbb{E} \max_i X_i - V \\ &= 0.5\mathbb{E} \max_i X_i . \end{align}Let us use this along with the definition of $V$ in Lemma 1:
\begin{align} Alg &\geq P V + (1-P) \mathbb{E} \sum_i b_i \\ &= 0.5 P \mathbb{E} \max_i X_i ~ + ~ (1-P) \mathbb{E} \sum_i b_i \\ &\geq 0.5 P \mathbb{E} \max_i X_i ~ + ~ 0.5 (1-P) \mathbb{E} \max_i X_i \\ &= 0.5 \mathbb{E} \max_i X_i \end{align}It's fun to compare the proofs for the median rule and the half-the-expected-value rule. In both cases, we start by noting the prophet's performance is at most the threshold plus the sum of expected bonuses. The algorithm gets the threshold with probability $P$ and sum of expected bonuses with at least $1-P$.
With the median policy, $P=0.5$ so we get a half-approximation on both contributions (though we didn't bound the relative sizes of the contributions). On the other hand, with the half-the-mean policy, we showed that each contribution is a half-approximation to the expected max (though we didn't bound the relative chance of getting each contribution).
Extensions
Now let's see how far we can push these proof techniques. We'll show that any threshold between the median and the mean works, and slightly more.
First, by merging a proof in Samuel-Cahn (1984) and the above proof of Kleinberg and Weinberg (2012), we can get this range of feasible threshold policies which generalizes both results.
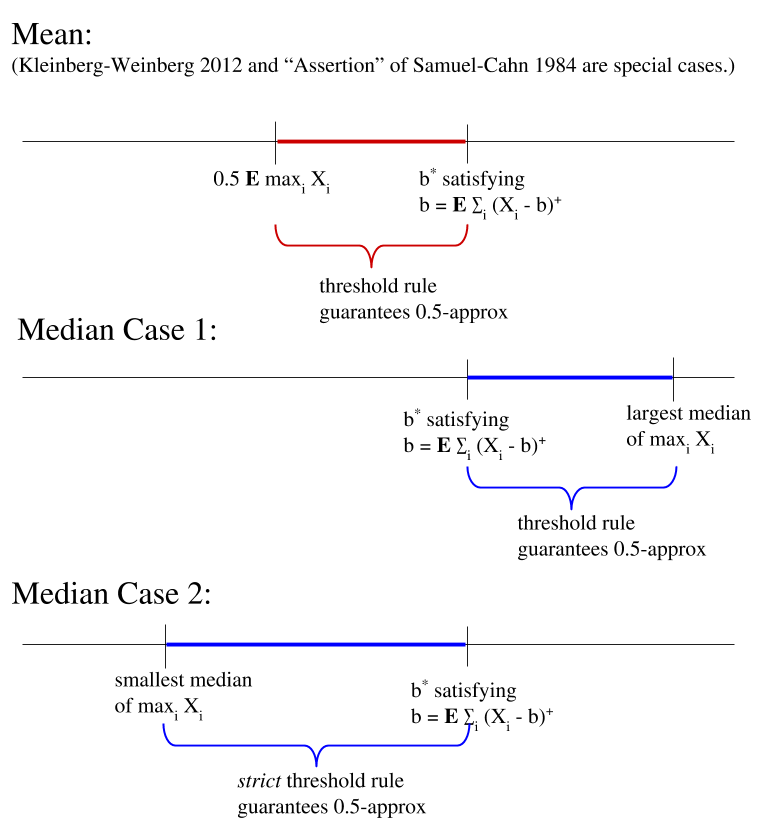
Theorem. If $V$ satisfies $0.5 \mathbb{E} \max_i X_i \leq V \leq \mathbb{E} \sum_i (X_i - V)^+$, then setting a threshold $V$ guarantees half of the maximum value in expectation.
(Exercise: check that this is always feasible. Hint: just check that $V = 0.5\mathbb{E} \max_i X_i$ satisfies both inequalities.)
Proof. Fixing $V$, recall our definitions of $b_i$, so we have the assumption $0.5\mathbb{E}\max_i X_i \leq V \leq \mathbb{E} \sum_i b_i$. For any such $V$, we have by Lemma 1 (recall $P = \Pr[\max_i X_i \geq V]$) \begin{align*} Alg &\geq P V + (1-P) \mathbb{E} \sum_i b_i \\ &\geq P V + (1-P) V \\ &= V \\ &\geq 0.5 \mathbb{E} \max_i X_i \end{align*} where the inequalities used our assumptions on $V$.
We can also extend the median threshold rules. I don't know of a particular reference for the next two, although I'm sure it has been worked out before.
Theorem. Let $m$ be the largest median of the maximum distribution, i.e. $m = \sup \{c : \Pr[\max_i X_i \geq c] \geq 0.5\}$. If $V$ satisfies $V \geq \mathbb{E} \sum_i (X_i - V)^+$ and $V \leq m$, then the $V$-threshold policy guarantees a half approximation.
Proof. By $V \leq m$, we get $P \geq 0.5$. We also have $V \geq \mathbb{E} \sum_i b_i$. So if we take Lemma 1: \begin{align} Alg &\geq P V + (1-P) \mathbb{E} \sum_i b_i \end{align} and shift some "weight" from the first term to the second, i.e. decrease $P$ to $0.5$ and increase $1-P$ to $0.5$, this only decreases the sum. \begin{align} Alg &\geq 0.5 V + 0.5 \mathbb{E} \sum_i b_i \\ &\geq 0.5 \mathbb{E} \max_i X_i \end{align} by Lemma 2.
Theorem. Let $m$ be the smallest median of the maximum distribution, i.e. $m = \inf \{c : \Pr[\max_i X_i \geq c] \geq 0.5\}$. If $V$ satisfies $V \leq \mathbb{E} \sum_i (X_i - V)^+$ and $V \geq m$, then the strict $V$-threshold policy guarantees a half approximation.
Proof. The strict threshold policy is to take the first variable strictly exceeding $V$. Strictness gives that $P \leq 0.5$, and now $V$ is the smaller of the two terms, so we have the same proof as above but shifting weight the other way:
\begin{align} Alg &\geq P V + (1-P) \mathbb{E} \sum_i b_i \\ &\geq 0.5 V + 0.5 \mathbb{E} \sum_i b_i \\ &\geq 0.5 \mathbb{E} \max_i X_i \end{align}Combining these gives, as far as I know, the widest known range of optimal thresholds for the standard prophet inequality problem.
Corollary. Let
- $V^*$ satisfy $V^* = \mathbb{E} \sum_i (X_i - V^*)^+$
- $\mu = \mathbb{E} \max_i X_i$
- $m,M$ be the lower and upper median of the random variable $\max_i X_i$.
In particular any value between the mean and the median works (but might need a strict threshold rule).
Open problem. Maybe the proof approach of Samuel-Cahn and Kleinberg+Weinberg is tight and these are all the thresholds that guarantee $0.5$. Problem: formalize this idea and prove it, or find another optimal threshold that is not a special case!
References
(1984) Ester Samuel-Cahn. Comparison of threshold stop rules and maximum for independent random variables. Annals of Probability.(2012) Robert Kleinberg and S. Matthew Weinberg. Matroid Prophet Inequalities. Proceedings of the Forty-fourth Annual ACM Symposium on Theory of Computing.